Tereza Pelikánová & Marcela Gruzová: Analýza kriminality v ČR a vliv dalších faktorů
Jak
jsme se daly dohromady?
Naše dvojička se náhodou seznámila již na úvodní hodině. Zbylo nám
místo vedle sebe a během čekání na úvodní focení a vyřizování dalších formalit,
jsme se daly do řeči. Zjistily jsme, že toho máme spolu vlastně hrozně moc
společného – lásku k letadlům, zdravému životnímu stylu, obě pracujeme i
studujeme a obě zde začínáme od 0, tedy bez předchozích znalostí programování
či datové analytiky. Během dalších hodin jsme si místo vedle sebe vybíraly záměrně
a stále více se upevňoval fakt, že naše dvojička už je asi jasná.
Jaký
byl náš plán?
Už na začátku jsme měly v plánu použít naše reálná data
z firmem, ve kterých pracujeme. Z toho jsme bohužel musely upustit,
protože oproti předchozím běhům byla letos změna – data nemůžeme mít svoje, ale
budou nám přidělena. Nijak nás to z míry nevyvedlo, na úvodním oficiálním
představení jsme poznaly spousty firem a očekávaly jsme tak velice zajímavá
data. Nemohly jsme se tak dočkat na hodinu představení dat. Po ní jsme znaly
témata, ne však strukturu dat. Ta nám měla být dodána až na hackathonu, abychom
měly všechny stejnou startovací pozici. Témata, která nám byla nakonec
odhalena, byla trochu jiná, než jsme očekávaly – méně témat od firem, více
obecných. Opět jsme tedy musely změnit směr, kam se naše další cesta bude
ubírat. Jedním z témat byl dataset týkající se informací o letištích,
autobusových nádražích, aerolinkách a vyhledávaných trasách. Jakožto velké
milovnice letadel jsme měly jasno. Jelikož jsme nevěděly přesnou strukturu, ale
Meet your mentor byl za dveřmi, začaly jsme vymýšlet možná témata a snažily se
je teoreticky propojit s dalšími zadanými – například s hlukovou
mapou. Pak přišel den Meet your mentor – pro nás spíš tedy studená sprcha. Dle
většiny mentorů byl náš nápad doslova na nic. Chtěli s námi diskutovat nad
strukturou dat a konkrétním propojením, ale my znaly jen název datasetů.
Naštěstí se našlo pár mentorů, kteří nás rovnou nezavrhli a nenechali
v zoufalé situaci, do které jsme se jako nováčci dostaly a snažili se nás
trochu nasměrovat. Po MYM jsme si stejně přišly ztracené – hned jak nám byl
přidělen mentor - Joe Šamánek - což byla volba, ze které jsme byly nadšené, sešly jsme se s ním abychom probraly data. Během toho
jsme již dostaly k nahlédnutí strukturu dat. Vize byla jasná – poupravit
naše téma z MYM, ale použít stále data o letectví. Jaké překvapení bylo,
když jsme do dat i s mentorem nahlédli, a shodli se, že jsou to spíše
doplňková data, než data, ze kterých by se dalo přímo vycházet. Začalo tedy
dlouhé hledání nových dat, a to už zbývalo jen pár dní do hackathonu! Dalším
nápadem bylo zkoumat vlivy zpoždění letadel – to už s tímto datasetem mělo
pramálo společného, ale propojit by se to asi dalo. My i mentor jsme hledali po
všech možných zdrojích nějakou databázi informací o odletech a příletech, ze
kterých bychom mohly čerpat informace o zpoždění, ale jediné, co jsme našli,
byla Amerika, což by asi pro využití v praxi nemělo význam, chtělo to
alespoň Evropu. Zkoušely jsme kontaktovat česká letiště, ale
z pochopitelných důvodů nám data poskytnout nemohly. Bohužel se nám
nezadařilo – mentor nám tedy doporučil, ať si vybereme jiné ze zadaných témat,
a to data z běžeckého e-shopu. „OK“, řekly jsme si, „alespoň to bude něco z praxe“.
BUM, další zklamání – data už má jiná dvojička a nejsou natolik obsáhlá, aby je
mělo více dvojic. Zbýval den do hackathonu. Naše zoufalost stoupala každou
hodinou. Podařilo se nám najít nějaká data o kriminalitě a o počasí, která by
snad použít šla. No, alespoň něco.
Jak
vzniklo naše aktuální téma?
Na hackathon jsme šly v pořádně pochmurné náladě – ráno jsme
neměly ani téma, ani jasná data, ze kterých budeme vycházet. Ráno jsme
s naším mentorem probrali možnosti a dohodli jsme se jasně – ze všeho
nejlíp nám vycházela kriminalita. V první hodině jsme si stanovily
základní otázky, které zněly:
· Jak se vyvíjela kriminalita v České republice a jednotlivých městech za poslední roky?
· Mají na kriminalitu vliv cizinci?
· Jaký má na kriminalitu vliv alkohol a drogy?
· Jak ovlivňuje kriminalitu nezaměstnanost a výše platu?
Jelikož je kriminalita hodně široký pojem – jen v našem
zdroji je konkrétně rozdělena na něco málo kolem 100 druhů činů, i na ty
opravdu ojedinělé, jako je „vražda na objednávku“, „okradení při znásilnění“ nebo
„získání kontroly nad vzdušným prostředkem“ – rozhodly jsme se proto zaměřit se
pouze na ty nejběžnější trestné činy, které jsme si stanovily na: celková
kriminalita, fyzické útoky, krádeže automobilů, krádeže jízdních kol, krádeže
věcí z automobilů, loupeže, vloupání do obydlí, vraždy, výroba, držení a
distribuce drog, zanedbání povinné péče a znásilnění. Chtěly jsme analyzovat
jak celou Českou republiku obecně, tak i její jednotlivá krajská města a jejich
přilehlé okolí. A jelikož jsme v Brně, tak jsme chtěly data i na
jednotlivé části Brna. Jenom s daty o kriminalitě jsme se tak dostaly na
275 tabulek, které jsme musely jednu po druhé stáhnout a vhodně pojmenovat,
abychom se v nich vyznaly – stahování bylo hladké, soubory byly
v CSV, avšak zabralo nám to celé dopoledne hackathonu.

Jedná z nás tedy stahovala tato data, druhá zase hledala a
stahovala data o nezaměstnanosti, cizincích a mzdách, kterými podpoříme naše
zadané otázky. To bylo dalších 50 tabulek. Jakmile jsme data měly stažené,
musely jsme prozkoumat, na základě, čeho je propojíme. Jediným klíčem bylo
město, které měly všechny tabulky shodné a roky. Tedy, většina tabulek byla
zaokrouhlena na roky, jenom data o mzdách byla v kvartálech. Jelikož tyto
tabulky byly o pár řádcích, použily jsme k úpravě a sjednocení excel.
Horší už to však bylo s tabulkami kriminality. Měly jsme 275 tabulek,
každá jedna tabulka pro konkrétní čin + území. Bylo tedy zapotřebí spojit je do
jedné. Na to už jsme potřebovaly silnější kalibr – zvolily jsme tedy python.
Náš mentor nám doporučil, ať na tyto práce s daty nepoužíváme Sublime,
který jsme využívaly do této doby, hlavně na hodinách při výuce, ale ať
použijeme Jupyter za využití knihovny pandas. Daly jsme na jeho rady, a tak
jsme data začaly zpracovávat a čistit v Jupyteru.
Nejdříve jsme si naimportovaly potřebné knihovny.

Ke spojení všech souborů jsme potřebovaly všechny CSV nahrát do jedné
složky. Během toho jsme zjistily, že název daného území máme pouze v názvu
souboru, nikoliv však v samotném sloupci – jakmile je spojíme, nebudeme
přeci vědět, kde se jaký čin stal! I s tím jsme si však pomocí pythonu
poradily.
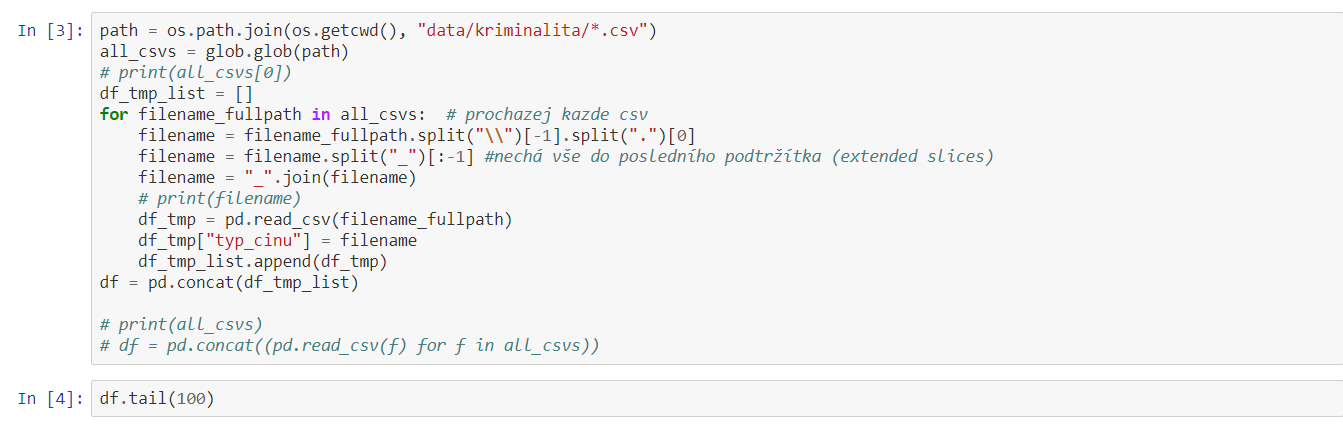

Bylo také potřeba si vhodně pojmenovat jednotlivé sloupce tak, aby
nám to v budoucnu dávalo smysl. Začínalo se nám pomalu rýsovat jedno
krásné CSV, které obsahuje vše, co nás zajímá. Po uložení jsme zjistily, že se
povedlo.

Bohužel však, dodělaly jsme toto a hackathon byl u konce. Byly
jsme rády, že na to, jak to ze začátku vypadalo zoufale, jsme se alespoň o
kousek posunuly. Po hackathonu nám začalo paradoxně ještě složitější období –
jedna z nás státnicovala, do toho samozřejmě práce a péče o své malé dítko
nepočká, té druhé běželo zkouškové období a rovněž práce, do toho povinné
výjezdy se školou. Najít si tak čas začalo být naším největším problémem – až
jsme záviděly těm holkám, co měly tu možnost věnovat se jen Digitální akademii
na plno. My bohužel takovou možnost neměly, ale i tak jsme v nabitém
programu díkybohu našly čas se sejít. Vím, že už to bylo psáno v mnoha
projektech před námi, ale digitální akademie je opravdu daleko náročnější a
intenzivnější, než se člověku zdá, když se přihlašuje.
Na dalších setkáních bylo načase dočistit ostatní data, která už
byla jen o pár tabulkách. Práce s našimi doplňkovými daty tak už byla sice
jednoduchá, ale stále docela zdlouhavá.
Například z tohoto:

Jsme dostaly přesně to, co jsme potřebovaly:

Jelikož jsme si chtěly vyzkoušet hlavně Power BI, natáhly jsme do
něj data s tím, že si ještě případné mouchy a nedokonalosti dočistíme tam.
A že bylo co čistit! Bylo například potřeba vyhledat a nahradit mínusové
hodnoty, které jsme musely vyřešit pomocí „Conditional column“. A během dalších
postupů jsme pokaždé na něco narazily – ale s tím jsme počítaly, nikdy to
není tak lehké, jak se dopředu zdá. Po veškerých potřebných úpravách dat mohl
následně vzniknout i náš datový model, který jsme doposud měly pouze na papíře.

A přešlo se k vizualizacím! Abychom v tom měly přehled,
rozhodly jsme se začít obecně kriminalitou vztaženou na celou ČR. Jelikož každá
data byla pro jiné roky, dohodly jsme se, že pro naši analýzu budeme
zohledňovat data za roky 2015–2018, ke kterým máme vhodné zdroje.
Jako první jsme zkoumaly vývoj trestné činnosti za roky 2015–2018.
Zjistily jsme, že kriminalita v posledních letech klesla oproti roku 2015
o 24 %. Roky 2017 a 2018 byly co se týče počtu trestných činů stabilní.

Kromě spáchání trestných činů nás zajímala také jejich
objasněnost. Z celkového počtu trestných činů za roky 2015–2018
(456 363 trestných činů) bylo okamžitě objasněno 24,78 % (159 362
trestných činů), dalších 4,27 % (27 478 trestných činů) bylo objasněno
dodatečně.

Co se týče četnosti trestných činů za již zmíněné období,
s přehledem vede Praha s 256 532 trestnými činy. S velkým
rozdílem za ní je Ostrava, která má na kontě 52 328 trestných činů. Třetího
místa se ujalo Brno s 50 551 trestnými činy. S výrazným rozdílem
pak následují ostatní města jako Plzeň, Liberec, Olomouc, Ústí nad Labem,
Pardubice, Zlín, Hradec Králové, České Budějovice, Karlovy Vary a Jihlava.


Další otázkou, která nás zajímala, byl vliv alkoholu na trestné
činy. Tato problematika se většinou řeší jen ve spojitosti s řízením
dopravních prostředků – my se však zaměřily i na ostatní trestné činy.
Z naší analýzy vyplývá, že pod vlivem alkoholu bylo spácháno nejvíce
fyzických napadení. Následovaly krádeže automobilů a loupeže.

Dále jsme zjišťovaly, zdali mají na kriminalitu vliv i další
faktory. První z nich byla výše mzdy. Pro tuto analýzu jsme si zvolily rok
2015. Naší hypotézou bylo, zdali v oblastech s nižší průměrnou mzdou
dochází k vyšší kriminalitě. Praha, která je na první místě
s nejvyšším počtem trestných činů, má zároveň nejvyšší průměrné mzdy.
Ostrava, která v kriminalitě zaujímá třetí místo, je s průměrnou
mzdou až na pátém místě.

Následně jsme pro stejnou tabulku použily data o nezaměstnanosti a
snažily se potvrdit/vyvrátit další hypotézu: je větší kriminalita tam, kde je i
větší nezaměstnanost? Tabulku jsme seřadily dle nezaměstnanosti – příčce vévodí
Ostrava, která je však v počtu trestných činů až na 3 místě. Druhá
největší nezaměstnanosti je v Ústí nad Labem, kde je překvapivě naopak
jedna z nižších hladin kriminality. Naopak Praha, která má největší
množství trestných činů, je v žebříčku nezaměstnanosti až na čtvrtém
místě.

Další otázkou bylo, zdali kriminalitu ovlivňuje výskyt cizinců.
Data, která máme k dispozici pro rok 2015 nám poskytují údaje o počtu
Rusů, Ukrajinců, Slováků a Vietnamců na našem území v jednotlivých
městech. Na křivku jsme pak promítly celkový počet trestných činů za rok 2015.
Na prvním místě v počtu trestných činů i cizinců se vyskytuje Praha. Na
druhém místě v trestných činech i přílivu cizinců je Brno, a v těsném
závěsu Ostrava.

Zobrazení pomocí těchto grafů je sice přehledné, ale zajímala nás
přesná korelace.
Použití
korelační analýzy
V dalším kroku jsme se tedy zaměřily na korelační analýzu –
ta posuzuje vzájemné vztahy pomocí korelačních koeficientů. Nejčastěji se
využívá Pearsonův korelační koeficient, který vyznačuje těsnost vztahu dvou
znaků ve vztahu k přímce. Pearsonův korelační koeficient se značí písmenem
r a nabývá hodnot od -1 do 1. Míru
závislosti podle tohoto koeficientu lze interpretovat pomocí násl. kritérií:
0,1 – 0,3 korelace slabá
0,4 – 0,6 korelace střední
0,7 – 0,8 korelace silná
nad 0,9 korelace velmi silná
K výpočtu Pearsonova korelačního koeficientu jsme použily
excelovský analytický nástroj Korelace.
Tento nástroj je obsažen v položce Analýza
dat.

Pokud tuto položku nemáte ve svém excelu, stejně jako my, je možné
ji nastavit pomocí těchto kroků: klikneme na ikonu Soubor, otevřeme Možnosti aplikace
Excel, vyberme položku Doplňky,
nastavíme Analytické nástroje jako Aktivní
doplněk k dispozici a klikneme na tlačítko Přejít. Zaškrtneme Analytické
nástroje a potvrdíme OK.

Pro samotný výpočet jsme pak použily následující cestu: přes
položku Data a v hlavním menu se nám
objeví nová položka Analýza dat: 1.
Klikneme na Analýza dat ze seznamu analytických nástrojů a vybereme položku Korelace.
Výsledkem tohoto procesu je tabulka, v jejíchž řádcích a
sloupcích jsou uvedeny všechny zkoumané znaky, čísla uvnitř matice jsou hodnoty
Pearsonova korelačního koeficientu pro zadanou dvojici znaků. Je zřejmé, že
nejsilnější pozitivní závislost je mezi celkovou kriminalitou a výskytem
cizinců v daném městě, pak také mezi celkovou kriminalitou a mzdou. Mezi
celkovou kriminalitou a nezaměstnaností se potvrdila pouze střední závislost,
avšak je zde také patrná.

Použití
regresní analýzy
Dále jsme se zaměřily na regresní analýzu – metoda regresní
analýzy hledá matematické vyjádření vztahu mezi zkoumanými znaky a dává odpověď
na otázku, zda lze jeden znak odhadnout na základě jiného nebo jiných znaků a s
jakou chybou. Regresní analýzu jsme použily opět v programu excel pro
ověření správnosti analýzy korelační.
Postup regresní analýzy lze shrnout do těchto bodů:
1. Sestrojíme bodový graf.
2. V řadě případů lze vztah popsat přímkou, zvolíme tedy typ
regresní křivky a vypočítáme její koeficienty. V grafu si také přidáme
spojnici trendu pomocí trendu lineárního a také si zatrhneme možnosti zobrazení
rovnice regrese a hodnota spolehlivosti.

3. Zhodnotíme kvalitu našeho řešení pomocí koeficientu determinace
neboli R2 . Tato hodnota nám udává procento, jakým je rozptyl hodnot
závisle proměnné veličiny Y (cizinci; nezaměstnanost; mzda) vysvětlen změnami
hodnot nezávisle proměnné veličiny X (celk_krim). Koeficient nabývá hodnot od 0
do 1. Čím je hodnota vyšší, tím je nalezený model kvalitnější. V případě
lineární regrese je koeficient determinace roven druhé mocnině Pearsonova
korelačního koeficientu. V našem případě byl koeficient determinace pro znaky celk_krim/cizinci R² = 0,8367, což je poměrně vysoké číslo, když jej převedeme do procentuální hodnoty, zjistíme, že námi vybraný lienární model byl vhodně zvolený. Totéž platí i pro výsledný koeficient determinace pro znaky celk_krim/mzda jehož hodnota je R² = 0,6218.
Pro kontrolu správnosti našeho řešení jsme použily dva postupy
výpočtů. První postup byl pomocí klasické funkce CORREL v Excelu pro každý
rok a každá znak zvlášť. Posléze jsme si hodnoty ještě graficky vyjádřily, také
pro ověření a kontrolu.

V druhém postupu jsme již nepoužily vzorce, ale analytické
nástroje Korelaci a grafické znázornění pomocí Regresní analýzy.
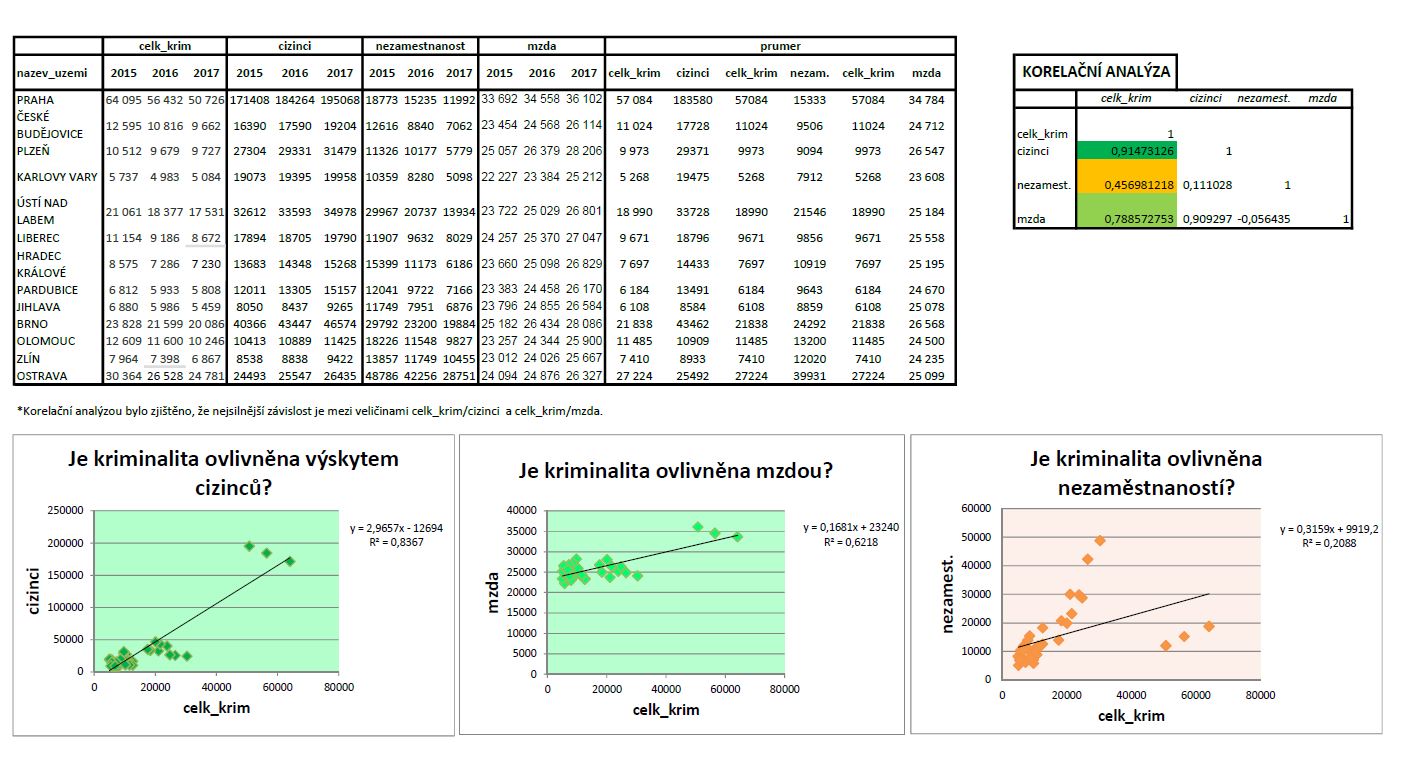
Je patrné, že oba postupy vyšly se stejnými výsledky.
A
co takhle nějaký prográmek na závěr?
Jelikož už jsme si v Power BI zodpověděly vše, co jsme si
stanovily a dostaly jsme od Czechitas nějaký ten čásek do odevzdání projektu
navíc, rozhodly jsme se v pythonu naprogramovat ještě prográmek, který
využije data pro skutečný přínos pro praxi – je možné jej využít například pro
realitní kanceláře či jakékoliv jiné subjekty, poskytující nemovitosti
v dané lokalitě/městě. Klient zadá lokalitu (zatím vztaženo na město, ale
pro budoucí využití se dá lokalita upřesnit třeba na danou ulici – po
zpracování a nahrání dalších konkrétních dat) a program mu vypíše informace o
průměrné výši mzdy, počtu nezaměstnanosti, počtu cizinců a kriminalitě. Veškeré
informace potom shrne do pořadí, ve kterém se dané město nachází.





A
jak to vypadá?
Odpověď po
zadání města Prahy vypadala takto:
Vážený kliente, zadejte město, které Vás
zajímá: "Praha"
Ve městě Praha je průměrná výše hrubé mzdy
34 784 Kč, nezaměstnaných je zde průměrně 15 333 osob, výskyt cizinců je zde
průměrně okolo 183 580 osob a počet trestných činů je ve výši 57 084 ročně.
Toto město je z hlediska výše mzdy na 1. místě, dle nezaměstnanosti na 1.
místě, dle výskytu cizinců na 5. místě a dle počtu trestných činů na 1. místě.
Chcete zvolit další město?
Ukázka
v příkazovém řádku:


Je den do odevzdání – a my konstatujeme celé šťastné: zvládly jsme to! Dokonce pro nás lépe, než jsme si vůbec na začátku dokázaly představit. Určitě tímto neplánujeme náš projekt odložit do šuplíku – ba naopak! Práce na něm nás bavila a teď když bude více času, čeká nás další výzva v podobě doplnění analýzy o další data, kterými můžeme rozšířit nejenom zkoumané otázky, ale také uživatelskou přesnost našeho prográmku. Hrozně moc bychom chtěly poděkovat našemu mentorovi, Joemu, za neskutečnou trpělivost a ochotu s jakou nám pomáhal. Digitální akademie je u konce, a i když to pro nás mnohdy nebylo lehké, jsme šťastné za to, co nám dala - bylo to jedno velké dobrodružství, poznaly jsme plno skvělých lidí a získaly mnoho nových informací. Jsme šťastné, že i přes slabé chvilky, které nás v průběhu postihly, jsme neztratily hlavu a dotáhly to do konce :-)

Je den do odevzdání – a my konstatujeme celé šťastné: zvládly jsme to! Dokonce pro nás lépe, než jsme si vůbec na začátku dokázaly představit. Určitě tímto neplánujeme náš projekt odložit do šuplíku – ba naopak! Práce na něm nás bavila a teď když bude více času, čeká nás další výzva v podobě doplnění analýzy o další data, kterými můžeme rozšířit nejenom zkoumané otázky, ale také uživatelskou přesnost našeho prográmku. Hrozně moc bychom chtěly poděkovat našemu mentorovi, Joemu, za neskutečnou trpělivost a ochotu s jakou nám pomáhal. Digitální akademie je u konce, a i když to pro nás mnohdy nebylo lehké, jsme šťastné za to, co nám dala - bylo to jedno velké dobrodružství, poznaly jsme plno skvělých lidí a získaly mnoho nových informací. Jsme šťastné, že i přes slabé chvilky, které nás v průběhu postihly, jsme neztratily hlavu a dotáhly to do konce :-)



{kind=link}
Podle mě jsou hlavním problémem velmi nízké trestní sazby. Lidi se dneska kriminálu nebojí a v tom je ten problém. A z toho kriminálu většinou vycházejí ještě horší, než tam jsou. Plus ty váhy jsou tak nějak divně nastavené. Za to, že někde na černou skládku vysypete třeba papírové kelímky dostanete skoro víc než za ublížení na zdraví.
OdpovědětVymazat