Lenka Švrčinová: Analýza obchodních výsledků v návaznosti na používání CRM systému
Než jsem se přihlásila do Digitální akademie, měla jsem o práci s daty jen velmi malé povědomí. Po práci v oblasti podpory exportu jsem nakoukla do IT světa a už bych se tu ráda usadila. Začínám pozvolna, zabývám se implementací CRM pro menší firmy, přípravou mailových kampaní v MailChimp nebo tvorbou webových stránek ve Webnode. Ale člověk nemusí být génius, aby tohle zvládal, chtělo by to něco sofistikovanějšího.
A protože se ráda učím nové věci, při jednom hledání on-line kurzů jsem objevila Czechitas, zrovna měl začínat dlouhodobější kurz Digitální akademie. Po pravdě, když jsem ho otevřela poprvé, dost jsem váhala. Většinu pojmů jsem slyšela poprvé v životě, jediný program na data, který jsem znala, byl Excel a jen jsem se modlila, aby byl kurz opravdu pro začátečníky, ne pro někoho, kdo s těmito programy pracuje "jen" pět, deset let. Ale nedalo mi to, vypravila jsem se na úvodní schůzku a přijela domů úplně nadšená. Za devět týdnů ze mě bude datová analytička (!). Natočila jsem motivační videovizitku, poslala vyplněný formulář a za pár týdnů sedla do lavic.
Ze začátku jsme do dozvěděli pár úvodních informací - jak vybírat projekt, kde čerpat data, kdo je to vlastně datový analytik a jak všichni (?), kdo to dělají, to vlastně nikdy nestudovali. Zdá se, že stačí zdravý selský rozum a Google. Po týdnu jsme v kavárně prezentovali své nápady na závěrečnou práci mentorům a po přidělení mentora jsme mohli začít na samotné práci.
V Excelu jsem pomocí funkce SVYHLEDAT přiřadila jednotlivým zákazníkům ID ze CRM systému, abychom je mohli v budoucnu jednoduše dohledat bez nutnosti archivovat číselník. Nahradila jsem i jména jednotlivých obchodníků a stejně tak jsem anonymizovala adresy zákazníků jejich rozřazením do jednotlivých okresů a krajů. To bylo trochu složitější, každý obchodník píše adresu svého zákazníka trochu jiným způsobem, někdy je město vlevo, někdy vpravo, jindy uprostřed. Nakonec jsem v přímo v CRM našla možnost převodu adres pomocí Google, rozdělila adresu na jednotlivé části a potom už to bylo víceméně jednoduché. Protože mají některé obce v ČR stejný název, použila jsem jako hlavní vodítko pro rozřazení PSČ a podle číselníku České pošty provedla přiřazení do příslušného okresu / kraje. Podle názvu obcí jsem rozřadila ty ostatní, jen jsem u duplicit zkontrolovala správnost.
Opatrně začínám pracovat. Podle přednášek připravím kostru tabulek a jejich vnitřek postupně nakopíruji do SQL.
Soubory postupně prohlídnu v SQL a všímám si, že mám v tabulce dvě hlavičky - připravenou i zkopírovanou. Ujistím se, že mám správně zapsán příkaz (SELECT * FROM PD_activity WHERE
ID_act = 'ID_act') a tenhle řádek úpravou příkazu smažu (DELETE FROM
PD_activity WHERE ID_act = 'ID_act'). První opravdový počin v SQL se povedl, to by mohlo jít..
Pro jistotu kontroluji, jestli se jednotlivé sloupce načetly správně (SELECT DISTINCT okres_org FROM PD_organization.. postupně pro všechny sloupce).
Nenačetly. V jednom sloupci se za každou položkou objevily dva středníky. Ty bych mohla vymazat při převodu do finálních tabulek. TO UMÍM.



Kdo tohle nezná, je šťastlivec, mně to dost snížilo sebevědomí..
No.. zase tak jednoduché to nebylo. Napadlo mě, že bych mohla porovnat, jestli obrat koresponduje s vynaloženým úsilím, ale chyběly mi údaje ve stejné struktuře, jako jsem měla u tabulky pro obrat (údaje o uskutečněných aktivitách rozdělené podle obchodníků a seskupené do jednotlivých měsíců). Nakonec jsem použila importní tabulku a zjistila jsem, že Power BI si s tabulkou poradí tak, jak je. Ve všech grafech jsem vybrala tři stejné obchodníky, označila je vždy stejnou barvou a v jednom grafu vyfiltrovala jen telefonáty a ve druhém jen osobní schůzky.
Z mého pohledu vztah mezi aktivitou (telefonáty, schůzky u zákazníků) a následkem v podobě vlivu na výši obratu vidět není, z velké části z důvodu, že dlouhou dobu po zavedení CRM nebyli jednotliví obchodníci v systému přiřazeni ke "svým" firmám a jeden obchodník nastoupil před rokem a část zákazníků i se svým obratem byla převedena na něj. Firma navíc přechází na plné využití CRM systému pozvolna, větší zapojení deklarují až od září 2017 (poslední zobáček v grafu), kdy nárůst aktivit i obratu viditelný je. Rozhodně by bylo zajímavé zpracovat tuhle analýzu později, abychom viděli dopad využití CRM systému na obrat firmy, což bylo mým hlavním cílem.
Pro vytvoření tabulky jsem použila stejný model jako u tabulky pro obrat obchodníků, jen jsem vybrala jiný sloupec z jiné tabulky.
Další tabulku mi pomohl sestavit mentor, z časových důvodů jsem se ani nesnažila ji vytvořit sama, ale doufám, že bych ke stejnému výsledku mohla dospět zdlouhavějším způsobem postupného vytváření tabulek. Novým pojmem je ISNULL(leden_2015,0), který mění hodnoty NULL na 0, kterou umí sčítat na rozdíl od NULL.
Po zadání tabulek do Power BI jsem vytvořila následující grafy:
V horním grafu vidíme vývoj jednotlivých segmentů po měsících, z posledního vývoje se zdá, že výraznější snaha o péči o firmy v segmentu A a B se pozitivně projevuje na celkovém obratu. Koláčový graf a popisky vpravo ukazují poměr jednotlivých segmentů dle výše vystavených faktur za sledované období. Stejné výsledky jsou vidět v tabulce vlevo dole (ta složitá..).
V grafu je rozdělení zákazníků na okresy (kolečka s velikostí podle obratu) a na kraje (podle barev). Města i kraje jsou podle grafů seřazeny podle výše obratu, není překvapením, že firma má největší obrat ve Zlínském kraji, kde má sídlo, a v Praze, kde má pobočku.
Každopádně by se mi moc líbila naznačená možnost zautomatizování celého procesu analýzy včetně publikování výstupu na webu, aby měla firma neustálý přehled o tom, jak si vede.
Práce s daty mě velmi nadchla, obzvlášť s Power BI jsem si ke konci vyhrála, ale jsem ráda, že jsem si mohla sáhnout i na MS SQL, za což děkuji svému mentorovi.
Své rodině děkuji za klid při práci a omlouvám se svému psovi, kterého mezitím nechali tito báječní lidé skoro vyhladovět.. :)
A protože se ráda učím nové věci, při jednom hledání on-line kurzů jsem objevila Czechitas, zrovna měl začínat dlouhodobější kurz Digitální akademie. Po pravdě, když jsem ho otevřela poprvé, dost jsem váhala. Většinu pojmů jsem slyšela poprvé v životě, jediný program na data, který jsem znala, byl Excel a jen jsem se modlila, aby byl kurz opravdu pro začátečníky, ne pro někoho, kdo s těmito programy pracuje "jen" pět, deset let. Ale nedalo mi to, vypravila jsem se na úvodní schůzku a přijela domů úplně nadšená. Za devět týdnů ze mě bude datová analytička (!). Natočila jsem motivační videovizitku, poslala vyplněný formulář a za pár týdnů sedla do lavic.
Ze začátku jsme do dozvěděli pár úvodních informací - jak vybírat projekt, kde čerpat data, kdo je to vlastně datový analytik a jak všichni (?), kdo to dělají, to vlastně nikdy nestudovali. Zdá se, že stačí zdravý selský rozum a Google. Po týdnu jsme v kavárně prezentovali své nápady na závěrečnou práci mentorům a po přidělení mentora jsme mohli začít na samotné práci.
Anonymizace
S firmou, se kterou spolupracuji, jsem se domluvila na možnosti zpracování jejich účetních dat a porovnání s daty ze CRM systému. Dostávám jeden soubor z účetního systému Pohoda, další dva si stáhnu ze CRM Pipedrive. Málokterá firma pustí do světa informace o svých výsledcích, proto bylo potřeba začít anonymizací dat.V Excelu jsem pomocí funkce SVYHLEDAT přiřadila jednotlivým zákazníkům ID ze CRM systému, abychom je mohli v budoucnu jednoduše dohledat bez nutnosti archivovat číselník. Nahradila jsem i jména jednotlivých obchodníků a stejně tak jsem anonymizovala adresy zákazníků jejich rozřazením do jednotlivých okresů a krajů. To bylo trochu složitější, každý obchodník píše adresu svého zákazníka trochu jiným způsobem, někdy je město vlevo, někdy vpravo, jindy uprostřed. Nakonec jsem v přímo v CRM našla možnost převodu adres pomocí Google, rozdělila adresu na jednotlivé části a potom už to bylo víceméně jednoduché. Protože mají některé obce v ČR stejný název, použila jsem jako hlavní vodítko pro rozřazení PSČ a podle číselníku České pošty provedla přiřazení do příslušného okresu / kraje. Podle názvu obcí jsem rozřadila ty ostatní, jen jsem u duplicit zkontrolovala správnost.
 |
| Excel - anonymizace sídla zákazníka pomocí SVYHLEDAT |
Příprava importních tabulek v SQL
Po první lekci SQL jsem trochu v rozpacích. Měla bych v něm zpracovávat ty tabulky, ale vůbec netuším, co se po mně chce. Chvíli odolávám, mentorovi se ozývám až po měsíci, kdy je jasné, že další lekce nebudou :-) .Opatrně začínám pracovat. Podle přednášek připravím kostru tabulek a jejich vnitřek postupně nakopíruji do SQL.
 |
| Command line - import tabulek do SQL |
Pro jistotu kontroluji, jestli se jednotlivé sloupce načetly správně (SELECT DISTINCT okres_org FROM PD_organization.. postupně pro všechny sloupce).
Nenačetly. V jednom sloupci se za každou položkou objevily dva středníky. Ty bych mohla vymazat při převodu do finálních tabulek. TO UMÍM.
Tvorba finálních tabulek
Aha, tak neumím.. |



Kdo tohle nezná, je šťastlivec, mně to dost snížilo sebevědomí..
Založila jsem si slovník chybových hlášek a pomocí Googlu odlaďovala všechny chyby (NOT NULL je nesmí být nuly nebo nevadí nuly??).
Nakonec jsem se s tím vším poprala a převod se povedl.
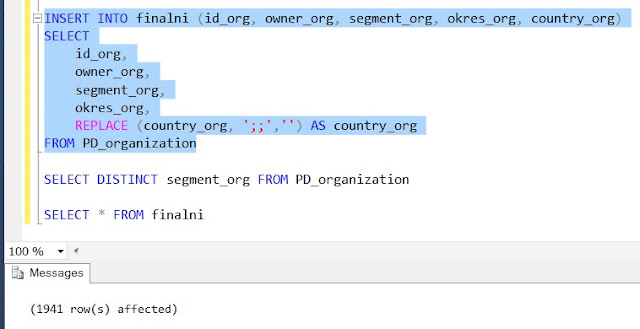 |
| SQL - vložení údajů z importní tablulk do finálni, zároveň odstraňujeme nechtěné středníky za názvy zemí |
No hurá.
Nastal čas na další lekci SQL. S mentorem Romanem se potkávám v kavárně a dostávám poměrně intenzívní tříhodinové školení. Chvíli se vzpamatovávám z přemíry informací, ale postupně mi některé věci dochází.
Takže zase od začátku.. příkazy mám sice uložené v počítači, ale píšu si je sama, protože SE TO UČÍM PRO SEBE a jen kontroluji a hledám chyby.
A tohle mě opravdu nadchlo: Není nutné složitě vypisovat příkaz v Command Line pro opakovaný import několika tabulek. Stačí si je nachystat do poznámkového bloku s příponou bat a pak jen kliknout na název souboru.
 |
| Poznámkový blok - hromadný import tabulek do SQL |
Načtou se samy:
 |
| SQL - výsledek importu |
Tvorba číselníků
Nejdřív si vytvořím číselník pro typ aktivit. Vytvořím prázdnou tabulku - první sloupec bude primární klíč s automatickým číslováním od jedničky, takže:
CREATE TABLE
t_type_act (
id_type_act INT IDENTITY (1,1),
type_act NVARCHAR (20) NOT NULL
)
Do tabulky vložím hodnoty z importní tabulky. První sloupec se bude číslovat automaticky, proto vypisuji jen příkaz pro druhý sloupec:
INSERT INTO t_type_act (type_act)
SELECT DISTINCT
SELECT DISTINCT
type_act
FROM import_activity
Obdobně pokračuji ve
tvorbě dalších číselníků - pro okresní města a pro státy: CREATE TABLE t_okres a INSERT
INTO. Objevuje se hláška "Cannot insert the value NULL into column
'okres', table 'PROJEKT.dbo.t_okres'; column does not allow nulls. INSERT
fails.", která mě upozorňuje na to, že mezi okresy jsou i NULL hodnoty,
ale v číselníku jsme nulové hodnoty zamítli (to je rovnou odpověď na dotaz, co znamená NOT NULL). Vyřeším úpravou dovětku WHERE ...
IS NOT NULL.
Tvorba finálních tabulek po stopadesáté
Začínám tabulkou final_activity. Tabulku vytvořím:
CREATE TABLE
final_activity (
ID_act int identity (1,1),
ID_org int not null,
date_act date not null,
owner_act nvarchar (50) not null,
type_act nvarchar (20) not null
)
Když zkontroluji
tabulku v Design table, mám pocit, že si se mnou SQL Management Studio hraje:
 |
| SQL - rozdíl mezi záměrem a výsledkem |
Nakonec se mi podaří
upravit datový typ i autoinkrementaci a do tabulky vložím údaje.
Kdybych
tvořila tabulku jen z importní tabulky, vypadalo by vložení dat následně:
INSERT INTO
final_activity (ID_org, date_act, owner_act, type_act)
SELECT
ID_org,
date_act,
owner_act,
type_act
FROM import_activity
Ale protože chci
tabulku propojit s vytvořeným číselníkem, přidám pod příkaz LEFT OUTER JOIN,
kterým označím, že chci tabulku propojit s číselníkem podle políček t_type_act
v obou tabulkách (LEFT OUTER JOIN t_type_act T ON T.type_act = I.type_act).
Písmenem T a I označuji alias příslušné tabulky (I = importní, T = číselník).
Stejná písmena použijeme i pro určení, který sloupec kopírujeme ze které
tabulky:
INSERT INTO
final_activity (ID_org, date_act, owner_act, type_act)
SELECT
I.ID_org,
I.date_act,
I.owner_act,
T.id_type_act
FROM import_activity
I
LEFT OUTER JOIN
t_type_act T ON T.type_act = I.type_act
Další tabulka bude
final_organization. Tady potřebuji, aby se mi ID_org zachovalo to, které mám
vytvořeno v rámci anonymizace - vynechávám autoinkrementaci.
CREATE TABLE
final_organization (
id_org INT NOT NULL,
owner_org NVARCHAR (50) NOT NULL,
segment_org CHAR(1) NULL,
okres_org INT NULL,
country_org INT NULL
)
A tabulku naplním
podobným způsobem jako v předchozím případu, jen mám dva JOINy.
INSERT INTO
final_organization (id_org, owner_org, segment_org, okres_org, country_org)
SELECT
I.id_org,
I.owner_org,
I.segment_org,
O.id_okres,
C.id_country
FROM
import_organization I
LEFT OUTER JOIN
t_okres O ON O.okres = I. okres_org
LEFT OUTER JOIN
t_country C ON C.country = I.country_org
Tabulku s účetními
daty necháme tak, jak je - není potřeba na ní nic měnit.
Konečně analýza
Vývoj aktivit v čase
Začnu něčím jednodušším. V SQL si připravím příkaz pro vyselektování jednotlivých typů aktivit, které zaměstnanci firmy zaznamenali do CRM systému, společně s datem vykonání aktivity.
Výslednou tabulku vložím do Excelu (CTRL A, CTRL C, CTRL V.. nic, co bych neuměla, ale nenapadlo by mě, že to jde uložit přímo z SQL). Uložím, nahraju do Power BI a hraju si. Po chvíli zkoušení mi přijde Power BI celkem intuitivní, snažím se vymyslet grafy, které budou nejvíce zajímavé pro firmu, která mi data poskytla.
V grafu nahoře vidíme vývoj jednotlivých druhů aktivit uskutečněných za celou dobu používání CRM, levý graf dole ukazuje aktivity za posledních 12 měsíců v sestupném uspořádání - pro zajímavost jsem vyfiltrovala jen aktivity uskutečněné po 31. říjnu 2016 (všechna data končila koncem letošního října). A v posledním grafu jde vidět zastoupení aktivit v jednotlivých měsících roku - z tohoto grafu jsem vyřadila aktivitu "nabídka", protože se ve firmě používá až od konce letošního srpna a výsledky by byly zkreslené.
 |
| SQL - vytvoření tabulky pro analýzu obchodních aktivit |
Výslednou tabulku vložím do Excelu (CTRL A, CTRL C, CTRL V.. nic, co bych neuměla, ale nenapadlo by mě, že to jde uložit přímo z SQL). Uložím, nahraju do Power BI a hraju si. Po chvíli zkoušení mi přijde Power BI celkem intuitivní, snažím se vymyslet grafy, které budou nejvíce zajímavé pro firmu, která mi data poskytla.
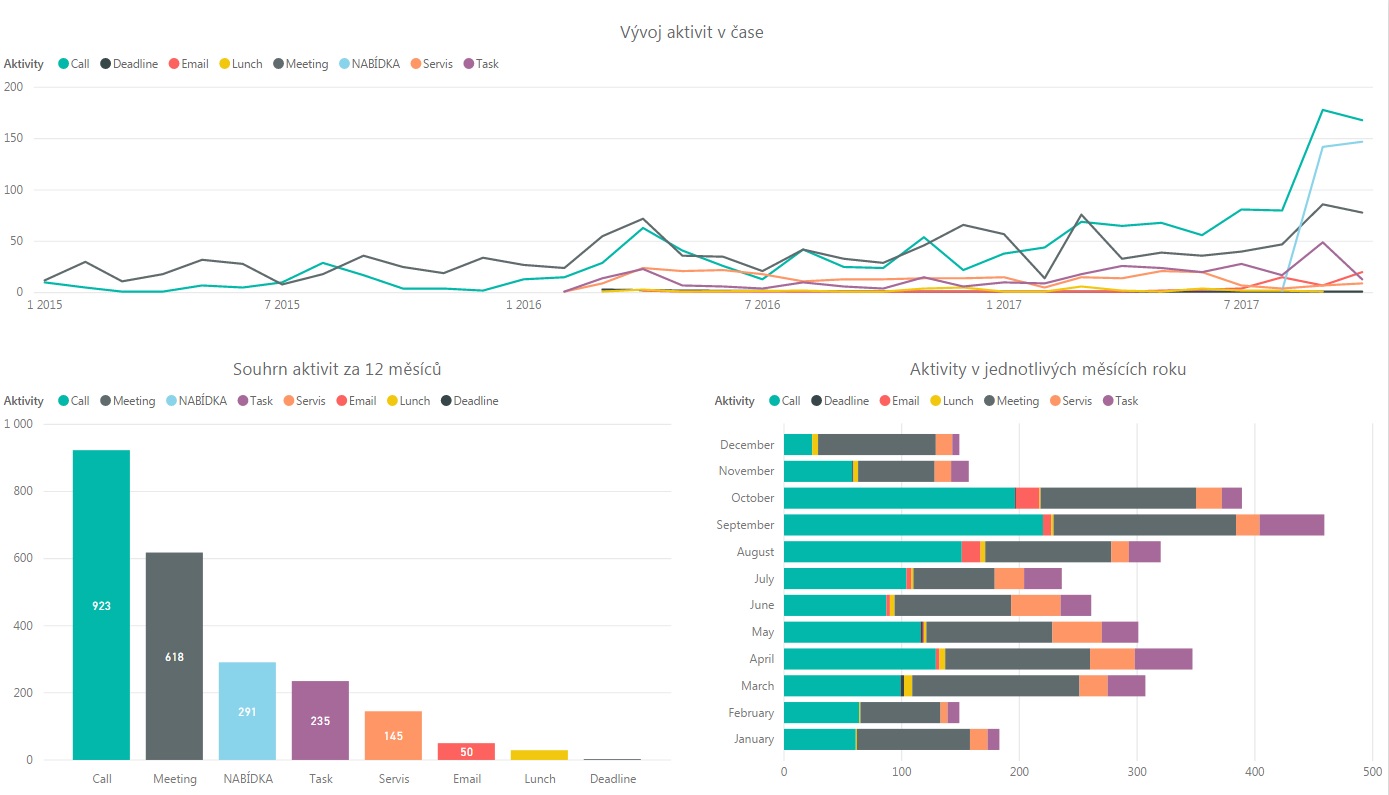 |
| Power BI - využívání CRM pro obchodní aktivity |
Obrat jednotlivých obchodníků v čase
Pro sestavení tabulky v SQL nejprve zkouším jen jeden
měsíc:
SELECT
owner_org,
leden_2015
FROM
import_organization I
LEFT OUTER JOIN
import_ucetnictvi U ON U.id_org = I.id_org
Vypíše všechny
organizace se svým ID, ke každé přiřadí ownera a jaký měli v lednu obrat.
Přidám GROUP BY owner_org, aby
se sečetly podle ownera, SQL radí, že je potřeba přidat "aggregate
function", přidám SUM (leden_2015) a protože to funguje, rozšířím i na ostatní měsíce.
V Excelu ještě upravím pro další použití - tabulku transponuju, přidám součty a můžu nahrát do Power BI.
 |
| SQL - vytvoření tabulky pro vývoj obratu jednotlivých obchodníků |
 |
| Power BI - porovnání obratu, schůzek a telefonických jednání ve stejném časovém úseku |
Z mého pohledu vztah mezi aktivitou (telefonáty, schůzky u zákazníků) a následkem v podobě vlivu na výši obratu vidět není, z velké části z důvodu, že dlouhou dobu po zavedení CRM nebyli jednotliví obchodníci v systému přiřazeni ke "svým" firmám a jeden obchodník nastoupil před rokem a část zákazníků i se svým obratem byla převedena na něj. Firma navíc přechází na plné využití CRM systému pozvolna, větší zapojení deklarují až od září 2017 (poslední zobáček v grafu), kdy nárůst aktivit i obratu viditelný je. Rozhodně by bylo zajímavé zpracovat tuhle analýzu později, abychom viděli dopad využití CRM systému na obrat firmy, což bylo mým hlavním cílem.
Vývoj obratu v jednotlivých segmentech
Od září 2016 začala firma používat rozdělení zákazníků na jednotlivé segmenty podle výše obratu - zákazníkům A, B, C je věnována větší péče než těm ostatním.Pro vytvoření tabulky jsem použila stejný model jako u tabulky pro obrat obchodníků, jen jsem vybrala jiný sloupec z jiné tabulky.
Další tabulku mi pomohl sestavit mentor, z časových důvodů jsem se ani nesnažila ji vytvořit sama, ale doufám, že bych ke stejnému výsledku mohla dospět zdlouhavějším způsobem postupného vytváření tabulek. Novým pojmem je ISNULL(leden_2015,0), který mění hodnoty NULL na 0, kterou umí sčítat na rozdíl od NULL.
 |
| SQL - vytvoření tabulky pro celkový obrat, průměrný obrat a počet faktur |
 |
| Power BI - obrat v jednotlivých segmentech |
Sídlo zákazníků - okres, kraj
Zajímalo mě, ze kterých míst má firma nejvíce zákazníků. Už v úvodu práce jsem si převedla sídla zákazníků na příslušné okresy a kraje, pokud chci provázání na obrat firmy, pomůžu si v SQL následujícím příkazem:
GitHub - ukázka kódu pro obrat v jednotlivých okresech
Vývoj v čase u jednotlivých obcí mi tolik zajímavý nepřijde, proto v Excelu dopočítám celkové součty a googlím, kde najdu mapu pro vložení do Power BI. Po vložení tabulky do Power BI zkouším jednotlivé mapy, než odpovídá výsledek mé představě.
 |
| Power BI - zákazníci v jednotlivých okresech / krajích podle obratu |
Zákazníci celosvětově
 |
| Power BI - zákazníci v jednotlivých zemích podle obratu |
Firma má zákazníky i v zahraniční, pro lepší přehled jsem vytvořila mapovou vizualizaci a filtrem zrušila Českou republiku. Zajímavými údaji ve vývoji zakázek podle obratu jsou prudký nárůst zájmu ze Slovenska v únoru 2017, kdy byl slovenský obrat vyšší než tuzemský a hodnoty z USA, které dosahují v "lepších" časech až polovinu obratu českých zakázek.
Přehled nejvýznamnějších zahraničních zákazníků podle zemí jsem vytvořila pomocí filtrovacího typu Top N s vyloučením České republiky.
Závěr
Moje práce s daty není zdaleka u konce. Čím více se blížím termínu odevzdání hotového článku, tím častěji mě napadá, co bych ještě mohla vylepšit, dodělávám nové tabulky, nové grafy, čtu články na internetu, sleduju videa.. Asi je dobře, že má práce i finální termín, jinak bych ji vylepšovala donekonečna.Každopádně by se mi moc líbila naznačená možnost zautomatizování celého procesu analýzy včetně publikování výstupu na webu, aby měla firma neustálý přehled o tom, jak si vede.
Práce s daty mě velmi nadchla, obzvlášť s Power BI jsem si ke konci vyhrála, ale jsem ráda, že jsem si mohla sáhnout i na MS SQL, za což děkuji svému mentorovi.
Své rodině děkuji za klid při práci a omlouvám se svému psovi, kterého mezitím nechali tito báječní lidé skoro vyhladovět.. :)
Zdroje
- zápisy z přednášek Czechitas a rady lektorů - Roman Baroš, Pavel Lasák, Honza Mayer
- Stack Owerflow
- Luboš Bednář (Intelligent Technologies) - Power BI - Part 1
- Luboš Bednář (Intelligent Technologies) - Power BI - Part 2
- Embedding Github code into your Blogger blog
- Mapa ČR pro vizualizaci v Power BI



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
No jsem teprve začátečník co se týká oboru IT ale to CRM jedná se tenhle systém? Teda jestli to chápu dobře tak se to dá použít třeba pro firmy co mají weby. A nebo třeba i pro nějaký e-shop. No jsem opravdu ještě začátečník ale vše se dá naučit.
OdpovědětVymazatMyslím si, že dneska by tohle všechno šlo už poměrně jasně automatizovat a dělat z toho přímo report. Na druhou stranu rozumím tomu, že pokud někdo pořád využívá software microsoft office 2013, tak ty možnosti jsou poměrně omezené. Ale na druhou stranu nalít to někam do Claudu není takový problém.
OdpovědětVymazat